
solyrion
무중단 배포 본문
들어가며
최근 AI 기반 회식 장소 추천 서비스를 개발하면서, 배포 과정에서 서비스를 멈추지 않고 업데이트하는 방법이 필요해졌습니다
설계 단계에서 서비스 특성상 단순히 배포 시간을 줄이는 게 아니라, 장애 영향 범위를 최소화하고 문제가 생겼을 때 빠르게 복구할 수 있는 배포 전략의 필요성을 느끼게 되어 무중단 배포를 단계적으로 도입하기로 했습니다.
초기에는 블루/그린으로 운영 안정성과 빠른 롤백을 확보하고, 이후에는 롤링 혹은 카나리로 전환해 일부 트래픽에서 먼저 검증하며 리스크를 더 작게 통제하고자 합니다.
이 글에서는 블루/그린, 롤링, 카나리를 각각을 설명하고 왜 우리 서비스는 블루/그린 → 롤링 or 카나리로 진화하려는지 정리합니다
무중단 배포란?
무중단 배포는 서비스를 멈추지 않고 새 버전을 배포하는 방식입니다
핵심 두 가지
- 다운 타임을 최대한 줄이면서 트래픽을 안전하게 새 버전으로 전환할 것
- 전환 중 문제가 생기면 빠르게 롤백할 것
이 목표를 달성하는 대표 전략이 블루/그린, 롤링, 카나리 입니다
1) 블루/그린 배포(Blue/Green)
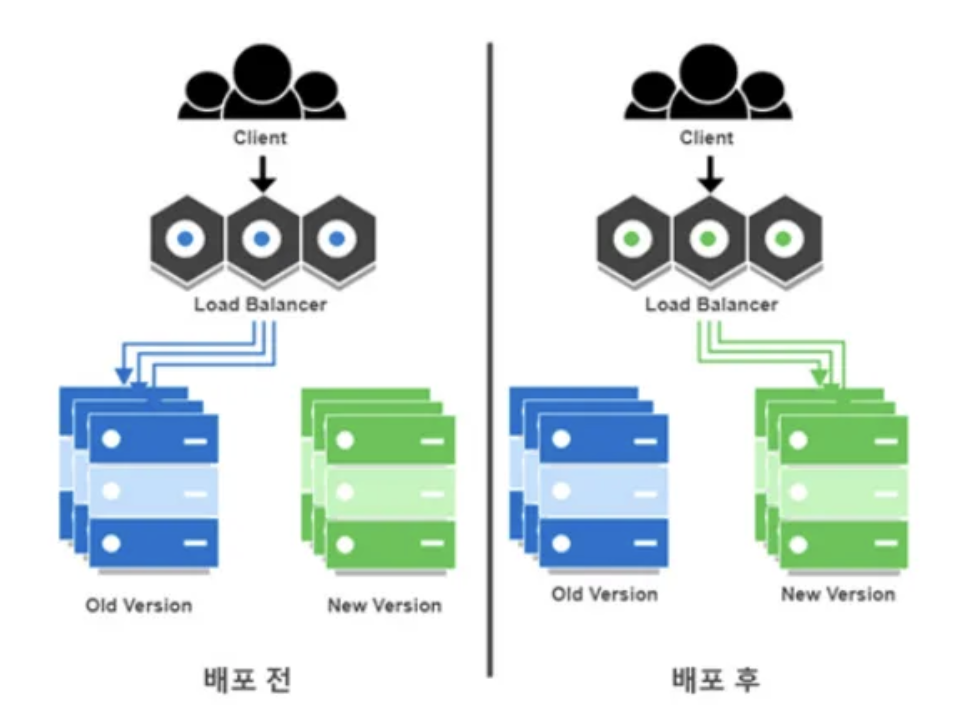
개념
동일한 운영 환경을 두 버전(Blue, Green) 유지합니다.
- Blue: 현재 운영 중(Stable)
- Green: 새 버전 배포 대상(Next)
새 버전을 Green에 올려서 헬스체크/스모크 테스트를 끝낸 뒤,
로드밸런서/라우팅을 한 번에 스위치해서 트래픽을 Green으로 넘기게 됩니다
(배포 전) Users → Blue
(배포 후) Users → Green
장점
- 스위치만 다시 Blue로 되돌리면 되기 때문에 롤백이 매우 빠름
- 배포 전 Green에서 실제 운영과 거의 동일한 환경 검증 가능
- 배포 시점이 명확해서 운영이 단순해짐
단점
- 운영 환경을 두 버전 유지해야 하기 때문에 비용이 2배로 필요
- 100% 트래픽이 한 번에 이동하기 때문에 스위치 순간에 문제가 터지면 대규모 영향
- 상태가 있는 시스템(세션/캐시/파일)에서는 전환 설계가 까다로움
- 예시: 세션 스토리지, 캐시 warm-up, 마이그레이션 호환성등
유용한 상황
- 빠른 롤백이 최우선인 초기 운영
- 배포 빈도는 높지 않지만 안정성이 매우 중요한 서비스
- 완전한 동일 환경에서 검증을 하고 싶을 때
2) 롤링 배포(Rolling)

개념
서버(인스턴스/파드)를 조금씩 교체하며 배포합니다
예를 들어 10대 중 2대씩 새 버전으로 바꾸고, 문제 없으면 다음 2대를 교체하는 방식
v1 v1 v1 v1 v1 → v2 v2 v1 v1 v1 → v2 v2 v2 v2 v2
장점
- 블루/그린 대비 추가 비용이 적음
- 똑같은 환경이 추가로 필요 없음
- 점진 교체라서 리소스 효율이 좋고 일반적인 운영 방식 중 하나
- 오토스케일/컨테이너 환경과 궁합이 좋음
단점
- 배포 중에는 v1과 v2가 공존 → 호환성 요구
- API 스키마/DB 컬럼/캐시 포맷이 깨지면 혼란
- 문제가 생겨도 어느 시점에 어떤 노드가 v2인지 추적, 복구가 번거로울 수 있음
- “중간 상태”가 길면 사용자 경험이 일관되지 않을 수 있음
유용한 상황
- 트래픽이 꾸준하고, 표준적인 운영/배포 파이프라인을 원할 때
- 컨테이너/오케스트레이션 환경(K8s 등)에서 기본 전략으로 쓰기 좋음
- 기능 변화가 비교적 단순하고, 호환성을 잘 지킬 수 있을 때
3) 카나리 배포(Canary)
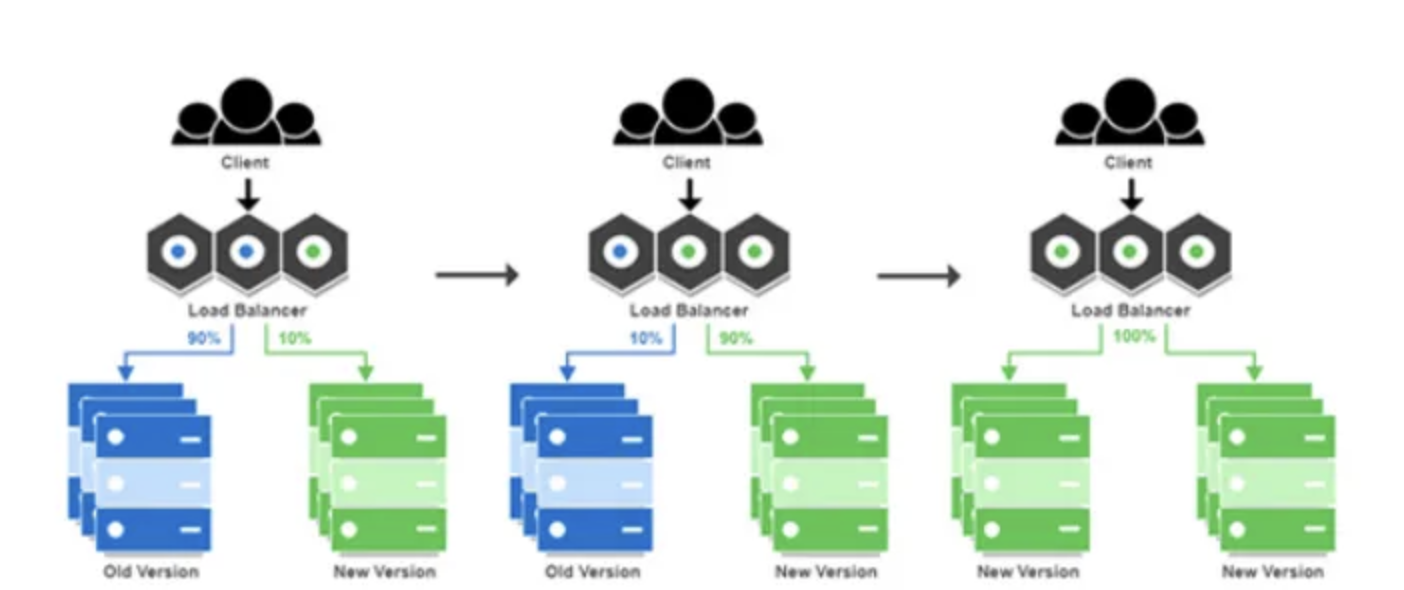
개념
새 버전을 전체에 뿌리지 않고 일부 트래픽에만 먼저 노출한다.
- 1% → 5% → 20% → 50% → 100% 처럼 단계적으로 확대
- 지표(에러율, p95 latency, CPU/mem, 전환율 등)가 기준을 넘으면 즉시 중단/롤백
Users → (99%) v1 + (1%) v2
→ (95%) v1 + (5%) v2
→ ...
장점
- 문제 발생 시 영향 범위를 작게 제한
- 실제 사용자 트래픽으로 검증하므로 신뢰도가 높음
- 기능 플래그/실험(A/B)과 결합하면 위험 관리 + 실험까지 가능
단점
- 트래픽 분배/관측/자동 중단 기준(SLO) 설계가 필요하기 때문에 운영 난이도 상승
- v1/v2 공존 기간이 길어질 수 있어 호환성 요구가 더 큼
- 로그/메트릭/트레이싱 같은 관측의 기준이 약하면 왜 실패했는지 파악이 어려움
유용한 상황
- 배포 빈도가 높고, 작은 변경이 자주 들어오는 제품
- 장애 비용이 크고, 리스크를 정량 지표로 통제하고 싶은 팀
- AI/추천/랭킹처럼 결과 품질이 중요한 기능을 안전하게 바꾸고 싶을 때
“AI 기반 회식 장소 추천” 에는 어떤 전략이 맞나?
이 서비스는 단순 CRUD만 있는 게 아니라, 보통 아래 특성이 있습니다.
- 트래픽이 시간대에 몰릴 가능성(회식 잡는 시간대)
- 추천/랭킹 로직 변경이 사용자 경험에 직접 영향
- AI/추천은 “정답이 없다” 보니, 실사용 지표로 검증이 중요
- 모델/피처/캐시/DB 스키마 변경이 섞이면 롤백이 단순하지 않을 수 있음
그래서 저희 팀은 초기에는 블루/그린으로 운영 안정성 확보 → 이후 카나리로 점진 진화가 합리적이라고 판단했습니다.
블루/그린 → 카나리로 점진적으로 바꾸는 이유
1) 초기에는 운영 안정성이 우선
서비스 초반에는 장애 한 번이 치명적일 수 있습니다
블루/그린은 배포가 단순하고, 문제가 생기면 스위치 한 번으로 즉시 복구가 가능합니다
즉, “운영을 안정화하는 단계”에서 강력합니다.
2) 하지만 추천/AI는 “실사용 검증”이 더 중요해진다
시간이 지나 기능을 고도화 할수록, 바뀌는 건:
- 추천 결과의 품질 변화
- 클릭/전환율 변화
- 지연 시간(p95) 변화
- 특정 조건에서만 발생하는 에러
이런 건 스테이징 테스트로 100% 예측이 어렵다고 생각합니다
카나리로 1~5% 실트래픽을 먼저 태워보면서 “실제 사용자 환경”에서 리스크를 제한한 채 검증할 수 있습니다
3) 블루/그린은 “한 번에 100% 전환”이라 위험이 커진다
초기엔 배포 안정성 때문에 괜찮지만, 변경이 커질수록 스위치 한 번에 전체가 바뀌는 구조는 부담이 됩니다
4) 카나리로 가면 “관측과 자동화”가 구축된다
카나리 도입 과정에서 자연스럽게 아래가 정리될 수 있습니다.
- SLI/SLO(에러율, p95 latency, 추천 클릭률 등)
- 배포 게이트(기준 넘으면 자동 중단)
- 로그/메트릭/알림 체계
- 기능 플래그/실험 문화
이건 한 번 구축해두면 이후 기능 개발 속도도 같이 올라갈 수 있습니다.
결론
- 블루/그린
- 단순하고 롤백이 빠른 초기 안정화에 강함
- 롤링
- 비용 효율적인 표준 운영
- 카나리:
- 실사용 기반으로 위험을 줄이는 “고도화/실험”에 최적
AI 기반 추천 서비스는 시간이 갈수록 정확히 동작하냐를 넘어 사용자가 더 좋아하는지가 중요해집니다.
그래서 초기에는 블루/그린으로 안전하게 운영 기반을 만들고, 운영 지표와 기준 및 자동화를 갖춘 뒤 카나리로 확장해 리스크를 통제하면서 개선 속도를 높이는 방향으로 설정했습니다.
'DevOps' 카테고리의 다른 글
| 트래픽 분산 (0) | 2025.12.27 |
|---|---|
| Spring Boot 빌드: GitHub Actions vs Dockerfile (0) | 2025.11.29 |
